





[h-index] 당신의 H는 무엇입니까?
h-index의 등장배경

h-index는 물리학자인 Jorge Hirsch에 의해 고안된 지표입니다. 특정 저자의 전체 논문수와 피인용수를 바탕으로 과학자(물리학자)의 연구성과, 공헌도를 하나의 수로 나타냅니다. '몇 편의 논문을 썼느냐'만으로는 연구자를 평가하기 어렵기 때문에 "피인용(논문이 다른 논문에 얼마나 인용되고 있느냐)"의 개념이 등장합니다. 그러나 피인용 수로 평가를 하는 것 또한 한계는 있습니다.
전체 피인용수가 100인 두 사람이 있다고 가정해봅시다. A라는 과학자는 현재 딱 한 편의 논문을 썼지만 100번의 인용을 받았고, B라는 과학자는 10편의 논문을 썼으며, 모든 논문이 각각 10번씩 인용되었다면 같은 평가를 받는 것이 적절한가? 이러한 의문에서 나타난 지수가 h-index입니다. 해당 연구자의 논문의 양과 질을 동시에 하나의 수치로 나타낼 수가 있는 것이지요.
h-index의 정의
R이라는 연구자의 h지수는, "R연구자가 출판한 전체 논문* 가운데, 피인용회수가 h이상인 논문이 h개를 채우는 수치"가 됩니다. 어설픈 번역을 시도하니 살짝~ 말장난 같지요? ㅎㅎ 예를 들어, h지수가 30인 연구자는 피인용회수가 30이상인 논문이 30편 있다는 것을 나타냅니다. (* 단, 선택하는 DB/기간에 따라 수치가 달라질 수 있겠지요)
h-index 쉽게 구하기
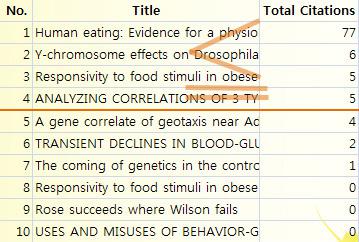
나의 h를 어떻게 구할 수 있을까? 아래 [표1]과 같이 자신의 전체 논문을 많이 인용된 순으로 정렬합니다. 왼쪽의 순번(No.)과 오른쪽의 피인용(Total Citations), 두 숫자를 비교하며 내려갑니다. 이때, 두 숫자가 같아지거나 비교했을 때 Total Citations가 순번보다 더 작아지기 시작하는 직전의 숫자(No.)를 찾아냅니다. 아래 연구자의 h는 "4"가 되겠지요?
Web Of Science와 h-index
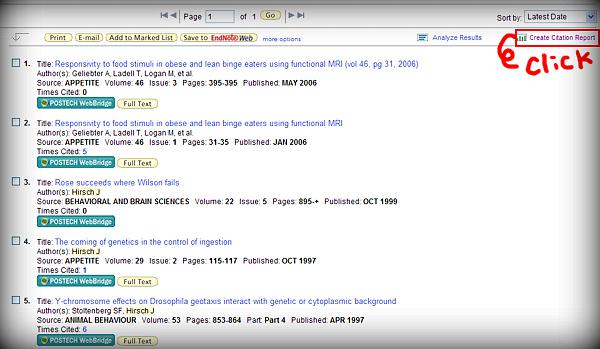
Web Of Science나 Scopus 등의 상용DB를 이용하셔서 검색결과로 간단하게 h-index를 구할 수 있습니다. 저자명 등으로 본인의 논문을 검색하여 걸러낸 후, "Create Citation Report" 클릭(하단의 [그림1]을 참고)
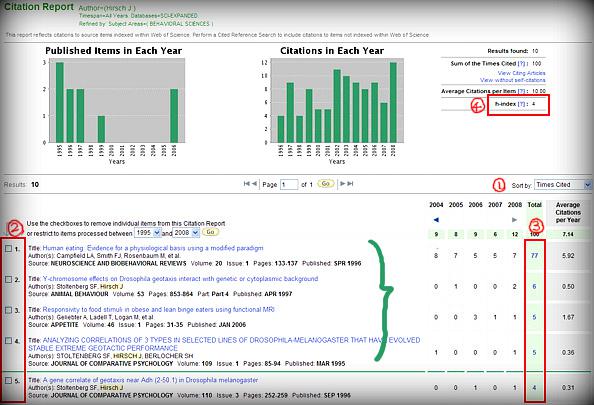
해당 연구자(저자)의 h-index를 포함한 아래와 [그림2]와 같은 "Citation Report"를 얻을 수 있습니다.
① 피인용수(Times Cited)로 정렬
② 정렬 후의 순번
③ 각 논문의 피인용수(Total Citations)
④ H-index
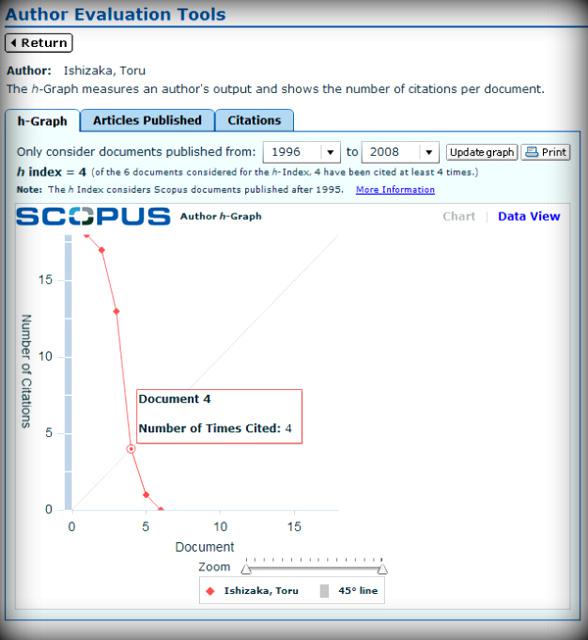
Scopus와 h-index
위와 유사한 방식으로 Scopus에서도 h-index 산출이 가능합니다. 저자의 "detail"보기로 들어가시면, h-index와 그래프가 제공됩니다. 저자명 만으로는 동일 연구자인지 판단하는 것은 쉽지 않기 때문에 기관(Affiliation), 주제 등으로 검색결과를 좁혀 정확한 데이터(논문)으로 인덱스를 산출하는 것이 가장 중요한 것 같습니다.
Google Based h-index Calcaulator
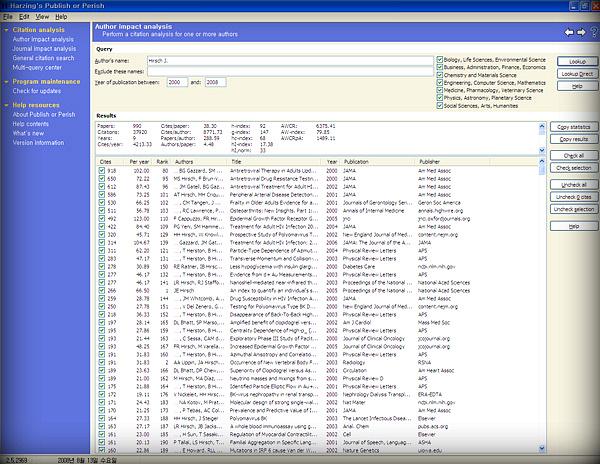
한편, 최근에는 Web Of Science, Scopus 등의 유료DB가 아닌 Google Scholar의 웹Citaion정보를 바탕으로 무료로 제공되는 프로그램이 등장하고 있습니다. 아래 [그림4]와 같이 저자명과 출판년도, 주제 분야 등으로 제한하여 검색하면 전체 출판 논문수, 전체 피인용 수, 년도/논문별 평균 피인용수, h-index, g-index 등의 다양한 평가지표를 한 번에 확인할 수 있습니다. Linux version도 제공합니다. 그런데 프로그램명이 조금 무시무시하네요;; "Publish or Perish"
h-index...&
h-index도 물론 완전한 완전한 평가방법이 될 수 없기 때문에, 최근 논문에 조금 더 힘을 실어주거나, 가장 많이 인용된 논문을 좀더 인정해 주는 등 점차 보강되면서 다른 평가방법들이 등장하고 있는 분위기 입니다. 그래도 연구자의 임용, 승진 등에 하나의 평가 툴의 하나로 활용되고 있는만큼 무시할 수는 없겠지요. 위에서 소개한 DB를 이용하여 구해보세요. 당신의 h는 무엇입니까?
Comments
h index 정의를 깔끔하게 정리해주셨군요. 잘
좋은 정보들이 참 많네요. 왕왕 들르도록 할께요.
계량정보학 수업을 듣게 됐는데 딱 필요한 정보인 것
왼쪽의 순번(No.)과 오른쪽의 피인용(Total