RSS News서비스 시작과 함께 진행한 이벤트의 당첨자를 알려드립니다. 상품이 부족했던지 참여가 저조해 당첨자를 선정하는데 많은(?) 도움이 되었습니다. 아직까지 RSS에 대한 인식과 우리나라 과학분야의 컨텐츠가 다소 빈약한 것은 아닌지 아쉬움이 남습니다.
당첨자에게는 개별 메일을 발송하겠습니다. 큰차이는 없지만 많은 분야의 피드를 제공하는 곳을 소개해주신 분에게 4GB의 메모리스틱을 드리겠습니다. 상품을 하나 걸었지만 나머지 분에게는 약소하지만 아차상으로 다른 상품을 준비했습니다. 앞으로 좋은 과학분야 RSS 피드가 있으면 언제든지 알려주시기 바랍니다.
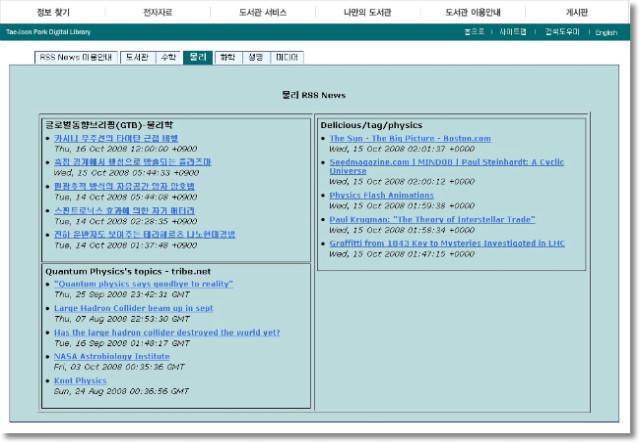
두분이 추천해주신 RSS 피드는 아래와 같습니다.
Eureka! Science News
http://esciencenews.com/
Eureka! Science News 라고 하는 서비스입니다.
과학의 거의 모든 분야를 다루고 있고, 분야별로 따로 RSS 서비스를 제공합니다.
추천 RSS feed : http://arxiv.org/rss/cond-mat
설명 : arxiv.org의 응집물질물리 paper rss feed
그 외에 astro-ph, cs, gr-qc, hep-ex, hep-lat, hep-ph, hep-th, math,
math-ph, nlin, nucl-ex, nucl-th, physics, q-bio, quant-ph, stat 등의 분야가
있는데 접속방법은 http://arxiv.org/rss/* <- *표에 해당 분야 이름을 쓰면 된다. 해당 분야는 http://arxiv.org 에서 확인할 수 있다.
2008-10-20 11:20